

新闻动态
【前文回顾】针对算力超节点这一新型计算基础设施,构建一套科学、可量化的综合效能基准指标体系,涵盖算力、网络、存储、稳定性与能效、运维五大维度,有效评估超节点的综合性能与竞争力。
本篇展望未来1至2年智算超节点的核心发展趋势,将深入剖析五大关键趋势:协议收敛、规模突破、互联革新、生态开放、软件适配。结合当前领先厂商的技术实践,探讨未来智算超节点的的技术演进路线图。
据IDC预测,2025年中国智能算力规模将达到1,037.3 EFLOPS,到2028年将进一步增长至2,781.9 EFLOPS,五年年复合增长率高达46.2% 。传统通过通用以太网连接标准化服务器,难以满足大模型分布式训练中高频次集合通信对带宽与时延的核心诉求。行业分析显示,传统架构下30%-50%的算力消耗于数据传输,时延居高不下,集群规模扩大后瓶颈愈发突出。超节点凭借高密度集成、高速互联、全局协同的核心优势,彻底打破“堆服务器扩算力”的旧模式,成为未来智算中心的核心部署形态。未来2年,超节点将向更高的传输带宽与计算性能、突破更大规模的 XPU 互联能力,以及构建更开放、更友好的全产业链生态,实现性能、规模与生态的协同升级。
趋势一:Scale UP互联协议收敛,开放标准引领主流
在超节点内部,连接成百上千个AI加速器的高速互联总线协议,是整个系统的“中枢神经”。当前,这一领域正处于一个群雄逐鹿的“战国时代”,多种协议并存,形成了封闭与开放两大阵营的激烈博弈。展望未来2年,Scale UP总线领域将逐步走向收敛,形成开放协议主导主流市场,封闭协议深耕极致性能场景的新格局。
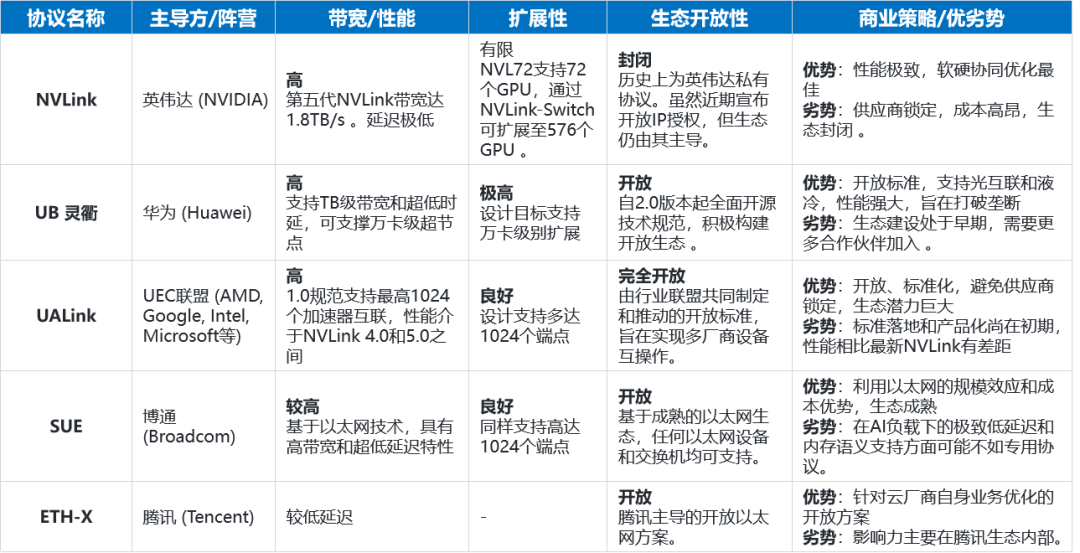
趋势二:千卡超节点成为新基准
①千卡超节点方案走向成熟与普及
主流的Scale-Up互联协议,如UALink、SUE、OISA等,其设计目标都将单超节点的最大节点规模定义在1024个,随着这些开放互联协议的相关上下游产业链的逐步成熟,为千卡超节点的普及铺平了道路 。全球主流的云服务商、AI硬件厂商以及系统集成商,均已将超节点作为其核心产品战略。例如,阿里巴巴的“磐久128超节点”(UPN512 全光互连架构将4个磐久128互联)、中科曙光的“ScaleX640超节点”、百度的“天池系列超节点(最高达512卡)”、中兴通讯的“Nebula星云智算超节点”以及浪潮信息的“元脑SD200超节点”,这些产品的相继发布和市场推广,标志着业界已经普遍接受并将超节点作为AI算力交付的基本单元 。这些方案虽然在初期规模上以数百卡为主,但其架构设计本身瞄准了向千卡以上的平滑扩展。
②万卡超节点竞赛开启,定义下一代算力巅峰
在千卡集群普及的同时,头部厂商已经将目光投向了规模更宏大、技术挑战更艰巨的万卡集群,这代表了未来2年内AI算力的巅峰形态。
趋势三:互联革新:光进铜退,破解通信墙瓶颈
①从电到光:必然的技术演进
随着交换机端口速率从400G/800G向1.6T/3.2T演进,传统电信号在PCB板上的传输距离被急剧压缩。为了将高速信号从交换芯片传输到前面板的可插拔光模块,需要经过复杂的PCB走线和Retimer芯片中继,这不仅带来了巨大的功耗(约占交换系统总功耗的50%),也限制了端口密度的提升。将光连接尽可能地靠近交换芯片,甚至与芯片封装在一起,成为必然选择。
②CPO/NPO共封装光学,引领互联革新
共封装光学(Co-Packaged Optics, CPO) 和 近封装光学(Near-Packaged Optics, NPO) 是这场革命的核心技术。
③全光大平层与光电混合协同
在超节点系统架构层面,CPO/NPO技术将催生新的网络拓扑。传统的胖树(Fat-Tree)等多层收敛型网络架构,在万卡集群中会导致跨越多级交换机的通信延迟累积。未来的超节点内部网络,将向全光大平层(All-Optical Flat Layer) 架构演进。在这种架构下,所有计算节点都通过光连接直接接入一个或多个核心光交换平面,实现任意两点间的“单跳”或极少跳数通信,彻底消除网络瓶颈。
当然,在机柜内部(Scale-Up),节点间可能仍采用高密度铜缆或板上光互联;而在机柜之间(Scale-Out)和机柜集群之间,则采用基于CPO/NPO的全光互联网络,构建一个无阻塞、低延迟的通信主干。
趋势四:超节点支持硬件解耦,更开放生态
长期以来,AI算力基础设施市场,尤其是在高性能计算领域,呈现出由少数厂商主导的垂直整合、软硬一体的封闭生态格局。然而,随着超节点规模的急剧扩张和应用场景的多样化,这种封闭模式的弊端日益凸显:供应商锁定风险高、创新成本高昂、系统灵活性差。
开放生态的核心诉求在于打破单一厂商的技术垄断,通过标准化、模块化的方式,为产业链各环节的参与者提供更广阔的创新空间和市场机会。腾讯的ETH-X开放超节点方案、字节跳动的大禹超节点等,都是大型互联网公司基于自身业务需求,推动基础设施开放化的典型实践 。Meta在开放生态建设方面走在最前列,其推出OCP加速模型(OAM),实现了系统中内存、计算、网络部件的全面解耦,使每一项都可以独立地进行扩展。OAM 标准允许 AMD、 Nvidia 和GraphCore 等多家厂商在统一规范上开发解决方案。这种开放架构不仅降低了技术门槛,更重要的是为用户提供了更多选择,避免了单一厂商锁定。
OCP(Open Compute Project)主导的Open Accelerator Module(OAM)规范定义了AI加速器的物理尺寸、电源接口、散热接口、管理接口,使得不同厂商的加速器可互换部署。UBB(Universal Baseboard)规范则定义了基板设计,支持8颗OAM加速器的互联。这些规范已被微软Azure、Meta、百度等大规模部署。
开放标准的技术特点体现在多个方面。首先是标准化设计,开放协议采用统一的技术规范,确保不同厂商产品的互操作性;其次是多厂商支持,通过开放标准吸引众多厂商参与,形成丰富的生态系统;第三是技术透明性,协议规范公开透明,便于各方理解和实现;最后是持续演进能力,通过开放的标准制定机制,能够快速响应技术发展和市场需求。关键部件解耦:计算、存储、网络的独立演进。
华为通过开源灵衢(UnifiedBus)协议展现了中国厂商在开放生态建设中的决心。华为的超节点架构与灵衢协议打破了传统封闭架构的格局,通过将硬件设计和互联协议全面开源,正在构建一个类似 "开源公路系统" 的算力生态 —— 任何企业都可以基于公开标准开发兼容产品,无需担心被单一供应商锁定。华为不仅开放了灵衢协议,还全面开放了超节点基础硬件,包括 NPU 模组、风冷刀片、液冷刀片、AI 标卡、CPU 主板和级联卡等不同形态的硬件,方便客户和伙伴进行增量开发。关键部件解耦是开放架构的核心特征,使得各子系统可独立选型、独立升级、独立优化,避免”牵一发而动全身”的系统性风险。
趋势五:异构算力协同与资源动态调度
①从同构到异构集成
超节点架构正从“单一加速器集群”向“异构计算集成”方向发展。英伟达NVLink Fusion技术允许第三方CPU和加速器通过授权方式接入NVLink生态系统,标志着即使是封闭生态的领导者也开始接受异构集成趋势。未来,超节点将进一步整合AI加速器、通用处理器、专用芯片(如NPU)等多元算力,根据工作负载智能调度最佳计算资源。
这种异构集成不仅体现在芯片层面,更将延伸至存储层级和网络架构。计算存储一体化(Computational Storage)技术允许在存储设备内直接处理数据,减少数据搬运开销。内存计算(Near-Memory Computing)和存内计算(In-Memory Computing)技术将部分计算功能嵌入存储层级,极大提升能效比。超节点将从简单的计算集群演进为“异构融合的计算综合体”,根据任务特征动态组织计算、存储和网络资源。
异构计算的成功关键在于高效的多芯片协同调度技术。通过智能的调度算法,可以将不同类型的计算任务分配给最适合的硬件资源,实现资源利用率的最大化。
研究表明,合理的异构调度可以将资源利用率提升30% 以上,显著降低算力成本。阿里云的异构算力调度系统支持 CPU、GPU、NPU 等异构资源的调度,通过强化学习模型预测任务需求,提高了资源利用率 30%,减少了任务延迟 20%。这种智能化的调度方式能够根据任务特征自动匹配最优的计算资源,避免了人工配置的复杂性和低效性。
趋势六:软件生态适配新型AI负载的编程新范式
注:SPMD 强同步、强一致、负载均衡的固有假设被打破,会导致大量设备空转等待、通信阻塞、算力利用率低下,无法高效适配MoE 与多模态架构中天然存在的负载不平衡问题。
为了解决这些问题,超节点亲和的AI 框架应运而生。这类框架将超节点视为单一逻辑计算机,并将硬件感知的编排嵌入到框架中。这种设计理念代表了 AI 框架发展的新方向,它要求框架不仅要支持传统的计算图优化,还要能够感知底层硬件的拓扑结构、内存层次、互联特性等,从而实现更高效的资源利用。
硬件感知型AI 框架的技术创新
硬件感知型AI 框架通过引入多项创新技术,实现了对超节点硬件架构的深度适配。
适配多样化AI 工作负载的技术路径
超节点需要支持的AI 工作负载日益多样化,包括大规模训练、实时推理、多模态处理、强化学习等。软件框架必须具备强大的适应性,能够为不同类型的工作负载提供最优的执行方案。
结语
从技术发展角度看,超节点规模将从当前的千卡级快速向万卡级甚至十万卡级演进,华为、谷歌等厂商已经展示了支持数万卡规模的产品能力。光互联技术将逐步取代铜缆成为主流,CPO/NPO 技术的成熟将彻底解决大模型 "通信墙" 问题。异构计算架构将全面取代同构系统,通过 GPU、NPU、ASIC 等多芯片协同,实现计算资源的最优配置。
从产业生态角度看,开放化和标准化将成为不可逆转的趋势。协议层面,开放型协议将逐步占据主导地位,封闭系统的市场空间将被压缩。OTT 厂商和行业组织正在推动硬件架构开放和解耦,打破传统厂商的技术垄断。软件框架将向硬件感知型演进,通过智能化的调度和优化,充分发挥新型硬件的性能潜力。




